| 统计学基础(一):中位数、方差、标准差、均方误差、估计量、高斯函数、正态分布 | 您所在的位置:网站首页 › 概率的平均数 中位数 众数怎么算 › 统计学基础(一):中位数、方差、标准差、均方误差、估计量、高斯函数、正态分布 |
统计学基础(一):中位数、方差、标准差、均方误差、估计量、高斯函数、正态分布
|
一、中位数
定义/解释:按顺序排列的一组数据中居于中间位置的数,即在这组数据中,有一半的数据比他大,有一半的数据比他小
# 如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。
方差(variance):是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量 2)应用 1、在统计描述中 方差用来计算每一个变量(观察值)与总体均数之间的差异 在许多实际问题中,研究方差即偏离程度有着重要意义 为避免出现离均差(X - 2、在概率分布中 用来度量随机变量和其数学期望(即均值)之间的偏离程度。 在概率分布中,设X是一个离散型随机变量,若E{[X - E(X)]2}存在,则称E{[X - E(X)]2}为X的方差,记为D(X),Var(X)或DX,其中E(X)是X的期望值,X是变量值,公式中的E是期望值expected value的缩写,意为“变量值与其期望值之差的平方和”的期望值。 离散型随机变量方差计算公式:D(X)=E{[X - E(X)]2} = E(X2) - [E(X)]2 当D(X) = E{[X-E(X)]2}称为变量X的方差,而 三、标准差 # 参考百科:标准差 1)定义 标准差(Standard Deviation)又常称均方差,是方差的算术平方根,反映一个数据集的离散程度 2)应用 在概率统计中:最常使用作为统计分布程度(statistical dispersion)上的测量。 标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。它反映组内个体间的离散程度 测量到分布程度的结果,原则上具有两种性质: 为非负数值, 与测量资料具有相同单位 一个总量的标准差或一个随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。 公式: 假设有一组数值X₁,X₂,X₃,......Xn(皆为实数),其平均值(算术平均值)为μ 标准差也被称为标准偏差,或者实验标准差,公式: 3)其它
简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值
3)其它
简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值
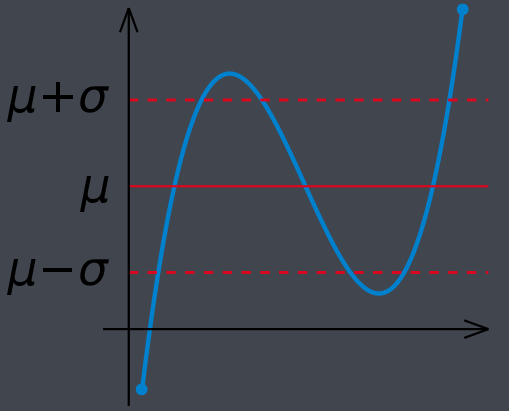 
四、均方误差 1)定义 均方误差(mean-square error, MSE)是反映估计量与被估计量之间差异程度的一种度量。 设t是根据子样确定的总体参数θ的一个估计量,(θ-t)2的数学期望,称为估计量t的均方误差。它等于σ2+b2,其中σ2与b分别是t的方差与偏倚。2)名词介绍 相合估计(或一致估计)是在大样本下评价估计量的标准,在样本量不是很多时,人们更加倾向于基于小样本的评价标准,此时,对无偏估计使用方差,对有偏估计使用均方误差。 一般地,在样本量一定时,评价一个点估计的好坏标准使用的指标总是点估计 均方误差是评价点估计的最一般的标准,自然,我们希望估计的均方误差越小越好,注意到
3)一致性最小的均方误差估计 定义1: 设有样本
五、估计量 1)定义 用来估计总体未知参数用的统计量。 在统计学中,估计量是基于观测数据计算一个已知量的估计值的法则:于是估计量(estimator)、被估量(estimand)和估计值(estimate)是有区别的。 估计值:当经测定的具体数值代入估计量时,它就是一个具体的数值,称为估计值,英文是estimator。 2)举例 设(X1,……,Xn)为来自总体X的样本,(X1,……,Xn)为相应的样本值,θ是总体分布的未知参数,θ∈Θ。 Θ 表示 θ 的取值范围,称 Θ 为参数空间。尽管 θ 是未知的,但它的参数空间 Θ 是事先知道的,为了估计未知参数θ,我们构造一个统计量 h(X1,……,Xn),然后用 h(X1,……,Xn) 的值 h(X1,……,Xn) 来估计θ的真值,称h(X1,……,Xn)为θ的估计量。
个人理解: 目的:估计总体数据集 X 的分布情况,即 θ; 方法:从总体数据集 X 中抽取一组样本 h,根据 h 的分布以及 θ 的取值范围 Θ 来估计总体数据集 X 的分布情况 θ。 3)误差 对于一个给定样本x,估计量 4)均方误差 估计量 5)一致性 一致估计量序列是一列随着序号(通常是样本容量)无限增大时依概率收敛于被估量的估计量序列。换句话说,增加样本容量增大了估计量接近总体参数的概率。 在数学上,一个估计量序列 {tn;n≥ 0} 是参数 θ 的一致估计量当且仅当对于所有 ϵ > 0,不管多小,我们都有
六、高斯函数、正态分布 1)定义 格式:
2)积分 任意高斯函数的积分是: 3)正态分布 参见百科:https://baike.baidu.com/item/%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83 公式:  正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution)
高斯函数是正态分布的密度函数,根据中心极限定理它是复杂总和的有限概率分布;
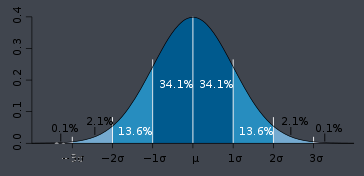
若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution)
高斯函数是正态分布的密度函数,根据中心极限定理它是复杂总和的有限概率分布;
若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
定理: 由于一般的正态总体其图像不一定关于y轴对称,对于任一正态总体,其取值小于x的概率。只要会用它求正态总体在某个特定区间的概率即可。 为了便于描述和应用,常将正态变量作数据转换。将一般正态分布转化成标准正态分布。 若 标准正态分布:当
|


【本文地址】
公司简介
联系我们